L'intelligence artificielle (IA) se réfère à la capacité d'un système informatique pour effectuer des tâches qui normalement nécessitent l'intelligence humaine. Cela inclut des capacités telles que l'apprentissage, le raisonnement, la résolution de problèmes, la compréhension du langage naturel, la perception visuelle et la prise de décision, avec l'objectif d'améliorer l'efficacité et l'automatisation.
L'intelligence artificielle s'appuie sur les données : la quantité, la qualité, et la diversité en sont des éléments cruciaux :
Quantité des données (Big Data) : L'IA bénéficie souvent de grandes quantités de données.Plus il y a de données à disposition, plus l'algorithme peut apprendre de modèles complexes et généraliser pour faire des prédictions ou des classifications sur de nouvelles données.
Qualité des données : La qualité des données est également essentielle. Des données de haute qualité garantissent que l'IA apprend à partir d'informations précises et fiables. Des données de mauvaise qualité peuvent conduire à des résultats incorrects et biaisés.
Diversité des données : Avoir une variété de données provenant de différentes sources ou représentant divers aspects d'un problème permet à l'IA d'avoir une compréhension plus complète et robuste, ce qui peut améliorer sa performance.
Les grands groupes et réseaux tels que Facebook ou Google qui disposent de vastes ensembles de données ont souvent un avantage en matière d'IA, car ils peuvent exploiter ces données pour former des modèles plus sophistiqués.
L'intelligence artificielle se décline en deux parties. La première est le Machine Learning, se basant sur l'utilisation des statistiques pour donner la faculté aux machines "d'apprendre", quant à la seconde partie appelée Deep Learning (apprentissage profond), il s'agit d'algorithmes capables de s'améliorer de façon autonome grâce des modélisations telles que les réseaux de neurones inspirés du fonctionnement du cerveau humain reposant sur un grand nombre de données. Le Deep Learning est donc une sous-catégorie du Machine Learning basée sur des réseaux de neurones artificiels. Par conséquent, lorsque nous parlons d’intelligence artificielle, il est préférable de parler de Machine Learning ou de Deep Learning. Dans cet article, nous nous focaliserons sur le Machine Learning, suivi du Deep Learning dans le prochain volet.
Plusieurs langages de programmation sont couramment utilisés dans le domaine de l'intelligence artificielle (IA), chacun ayant ses avantages et ses applications spécifiques. Cependant, Python reste le langage dominant dans le domaine de l'IA. Il est devenu le langage de prédilection pour de nombreux projets d'IA en raison de sa syntaxe simple, de sa lisibilité et de sa grande communauté de développeurs. Dans cet article, nous utiliseront Python comme outil pratique pour illustrer les diverses notions théoriques liées à l'intelligence artificielle.
2. Statistiques
Nous allons aborder une notion essentielle à tout projet de Machine Learning : l'utilisation des statistiques pour la compréhension des données. Les algorithmes d’apprentissages sont fondés sur diverses approches statistiques permettant aux machines d’apprendre, de réaliser des prédictions et de résoudre des problèmes.
En statistiques, on analyse des individus, pouvant être des personnes ou des objets, et chacun a ses caractéristiques. En Machine Learning, on les nomme "observations", et leurs caractéristiques sont appelées "features". Une "observation" est simplement un point de données dans un ensemble, utilisé pour entraîner ou tester un modèle. Les notions de base en statistiques incluent plusieurs concepts clés qui sont souvent utilisés dans le domaine de l'analyse de données. Voici quelques-unes des notions fondamentales :
Moyenne : C'est une mesure centrale qui représente la tendance centrale des données.
Médiane : La médiane est la valeur du milieu d'un ensemble de données triées par ordre croissant. Elle divise l'ensemble en deux parties égales.
Mode : Le mode est la valeur qui apparaît le plus fréquemment dans un ensemble de données.
Écart type : L'écart type mesure la dispersion des valeurs autour de la moyenne. Une faible déviation standard indique une concentration des valeurs autour de la moyenne.
Distribution : La distribution décrit la manière dont les valeurs sont réparties dans un ensemble de données.
Corrélation : La corrélation mesure la relation linéaire entre deux variables.
Régression : La régression analyse la relation entre une variable dépendante et une ou plusieurs variables indépendantes.
Échantillonnage : L'échantillonnage est le processus de sélection d'un sous-ensemble de la population pour tirer des conclusions générales sur la population entière.
Test d'hypothèse : Les tests d'hypothèse sont utilisés pour évaluer si une assertion sur une population est statistiquement significative.
Ces notions constituent une base solide pour comprendre et interpréter les données dans divers contextes statistiques.
Une machine est capable d’apprendre selon trois formes d’apprentissage, chacun adapté à des situations spécifiques :
3.1 Apprentissage supervisé
Dans l'apprentissage supervisé, le modèle est entraîné sur un ensemble de données labellisées (étiquetée) par l’être humain, où les entrées sont associées à des sorties connues. L'objectif est d'apprendre la relation entre les entrées et les sorties afin que le modèle puisse généraliser et prédire correctement les sorties pour de nouvelles entrées non labellisées.
Par exemple, dans ce modèle d'apprentissage, imaginons un système capable d'identifier des fruits à partir d'images. L'objectif serait d'enseigner à la machine à reconnaître et classifier des fruits tels que pommes, oranges, ou bananes en fonction des caractéristiques visuelles présentes dans les images. Lorsqu’il s’agit de prédire une valeur, nous parlerons alors de régression, dans le cas contraire, nous parlerons de classification. Prédire le prix d'un logement en fonction de ses caractéristiques, cela relève de la régression. En revanche, si le but est de déterminer si une image contient une personne, un animal ou un objet spécifique, nous parlons alors de classification.
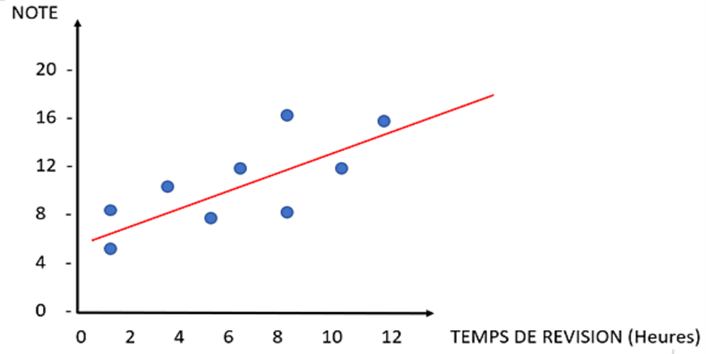
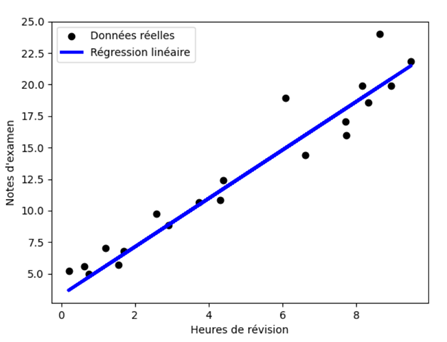
L'algorithme de régression linéaire univariée (Linear regression) est une technique d'apprentissage supervisé utilisée pour modéliser la relation entre une variable dépendante (la variable que l'on souhaite prédire) et une seule variable indépendante (la variable explicative). Par exemple, prédire une note à un examen (variable dépendante) en fonction du nombre d’heures de révisions (variable explicative). L'objectif est de trouver la meilleure approximation linéaire de la relation entre ces deux variables. La figure suivante représente les données d'une série d'observations sous forme de points, et l'on cherche à trouver une droite passant au plus près de ces points.
Régression linéaire univariée
L’algorithme régression linéaire multiple (Multiple Linear Regression-MLR) est une extension de la régression linéaire simple, où plusieurs variables explicatives sont utilisées pour prédire une variable cible. Contrairement à la régression linéaire univariée qui utilise une seule variable explicative, la MLR permet d'explorer des relations plus complexes, comme prédire le prix d'une maison tenant compte de plusieurs facteurs tels que la superficie, le nombre de chambres, la proximité des transports en commun, etc. Lors de l'utilisation de plusieurs variables, la normalisation est cruciale pour assurer une comparaison équitable des différentes échelles de ces variables.
Contrairement à la régression linéaire qui utilise des relations linéaires, la régression polynomiale (Polynomial regression) inclut des termes polynomiaux pour capturer des tendances non linéaires. Elle s'avère utile pour modéliser des phénomènes où la relation entre les variables ne suit pas une ligne droite, mais plutôt une courbe ou une tendance plus complexe. Par exemple, la régression polynomiale pourrait être utilisée pour modéliser la croissance d'une plante en fonction du temps, capturant ainsi des relations non linéaires telles que des phases de croissance accélérée ou ralentie.
L'algorithme de l'arbre de décision (Decision tree) est une méthode d'apprentissage supervisé utilisée dans divers domaines pour la classification et la régression. Il fonctionne en divisant progressivement les données en sous-groupes plus petits en fonction des caractéristiques pertinentes, jusqu'à ce que chaque sous-groupe représente une décision ou une classe particulière. Par exemple, cet algorithme pourrait prédire si une personne achètera ou non un produit en fonction de critères tels que son âge, son revenu, et ses habitudes d'achat. Cette méthode segmente les données pour déterminer les caractéristiques influençant la décision d'achat.
L'algorithme de la forêt aléatoire (Random forest) crée plusieurs arbres de décision en introduisant des éléments aléatoires pour diversifier les prédictions. En combinant les résultats de ces arbres, il fournit une prédiction plus précise et stable. Il est aussi utilisé dans le cadre de la classification.
Naive Bayes est un algorithme probabiliste simple basé sur le théorème de Bayes. Il calcule la probabilité qu'un événement se produise en fonction des probabilités conditionnelles préalables, c'est-à-dire en fonction d'un événement qui s'est déjà produit. Naive Bayes suppose que les caractéristiques utilisées pour la classification sont indépendantes, même si cela peut ne pas être vrai dans la réalité. Il est couramment utilisé pour la classification de texte et de documents, par exemple, la classification d'emails en spam ou non spam en fonction des mots qu'ils contiennent. Si l'email contient les mots "gratuit" et "offre", il est plus probable d'être classé comme spam.
3.2 Apprentissage non supervisé
L'apprentissage non supervisé s'effectue sur des ensembles de données non labellisées. Le modèle cherche à découvrir des structures fondamentales dans les données, comme des groupes de similarités ou des motifs. Il incombe donc à la machine de déterminer automatiquement ces groupes d'appartenance, également appelés clusters. La machine est ainsi capable de regrouper les données et d'effectuer des classifications, mais elle ne peut pas attribuer elle-même des libellés distincts, car elle n'a pas conscience des données dont elle est chargée d'apprendre.
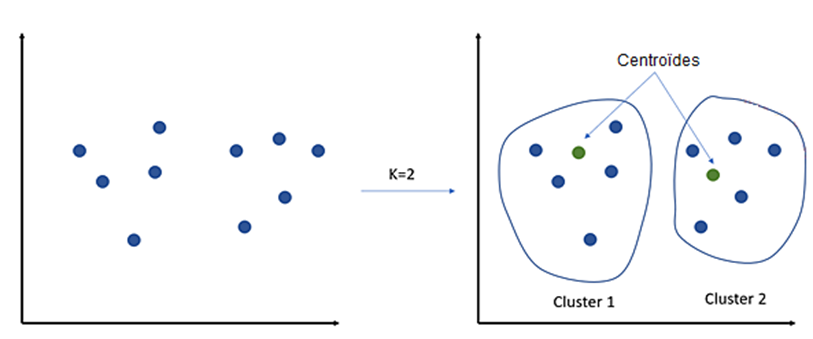
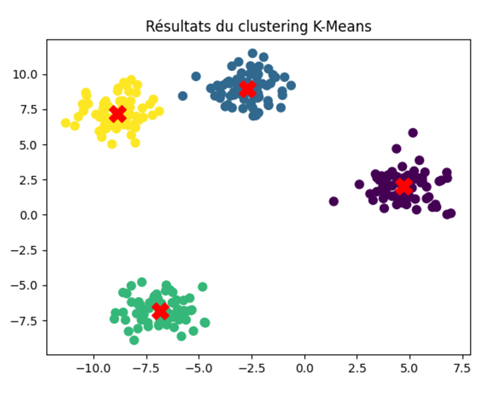
Parmi les algorithmes d'apprentissage non supervisé, l'algorithme des K-Moyennes (K-means) se distingue comme l'un des plus utilisés. Il nécessite la spécification préalable du nombre de clusters à identifier. À travers des itérations successives, l'algorithme cherche à déterminer des centroïdes (un par cluster) autour desquels les données peuvent être regroupées. En utilisant la distance entre chaque observation et un point central, appelé centroïde, l'algorithme classe automatiquement les observations en plusieurs groupes. Cette approche est illustrée dans la figure suivante, où l'algorithme a été configuré pour classer les observations en deux clusters, atteignant cet objectif en identifiant automatiquement deux centroïdes pour diviser les observations en deux groupes distincts.
Algorithme de K-Moyennes
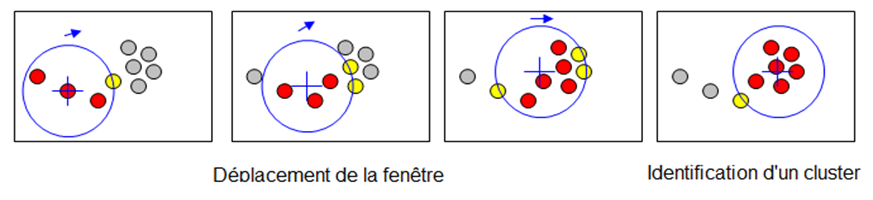
Mean-shift est un autre algorithme de clustering sans paramètre préalable qui identifie automatiquement les centres de densité maximale dans un ensemble de données. Il déplace itérativement des "fenêtres" (appelé Kernel) vers les zones de densité la plus élevée, regroupant ainsi les points convergents dans des clusters. C'est une méthode adaptative qui ne nécessite pas la spécification préalable du nombre de clusters (figure suivante).
Algorithme Mean-Shift
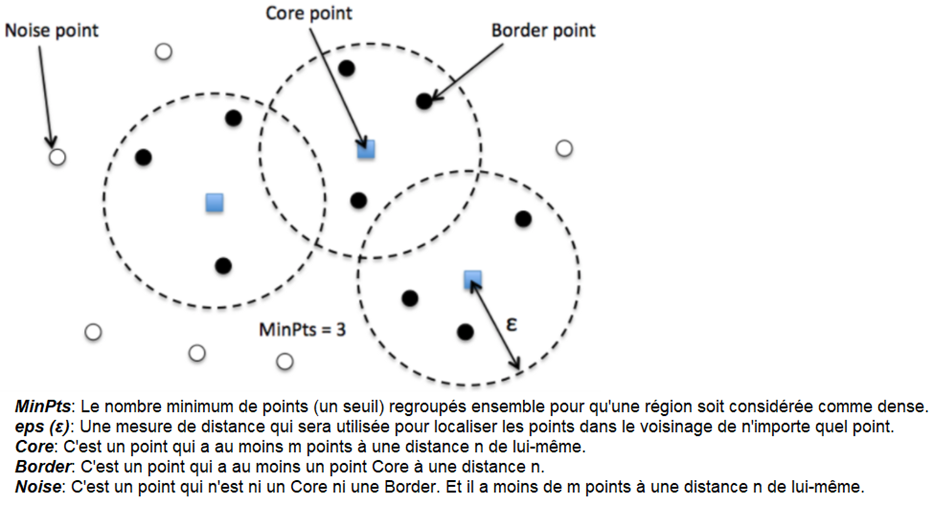
Tout comme l'algorithme Mean-shift, DBSCAN (Density-Based Spatial Clustering of Applications with Noise) se fonde sur la densité des observations pour identifier les clusters. Cependant, DBSCAN adopte une approche différente en évaluant la densité des points dans l'espace. Il recherche des "points centraux" entourés d'au moins un nombre minimum de voisins dans une certaine distance. Les points ne répondant pas à ces critères sont considérés comme du "bruit". DBSCAN est flexible, capable de détecter des clusters de formes variées sans nécessiter la pré-spécification du nombre de clusters.
En bref, DBSCAN se focalise sur la densité des points, tandis que Mean-shift recherche les centres de densité maximale dans les données. Le choix dépend des caractéristiques spécifiques de l'ensemble de données.
3.3 Apprentissage par renforcement
L'apprentissage par renforcement implique un agent qui prend des décisions dans un environnement pour maximiser une récompense cumulée. L'agent apprend par essais et erreurs, ajustant ses actions en fonction des récompenses obtenues. C'est souvent utilisé dans le domaine des jeux, de la robotique et de la prise de décision automatisée. Par exemple, un robot aspirateur intelligent qui prend des actions telles que se déplacer dans une pièce, éviter les obstacles et nettoyer des zones spécifiques. Lorsqu'il effectue des tâches efficacement, il reçoit des récompenses, mais des pénalités sont données en cas de comportement inefficace. Au fil du temps, le robot apprend à optimiser son comportement pour maximiser les récompenses, ce qui se traduit par un nettoyage plus efficace et une meilleure navigation dans l'environnement domestique.
Nous avons parcouru et décrit brièvement les différents algorithmes du Machine Learning les plus rencontrés et évoqués. Bien entendu, il en existe d’autres. Nous n’avons pas non plus évoqué les réseaux de neurones que nous aborderons en détail dans le prochain volet.
4. Applications Pratiques de Machine Learning avec Python
Ce chapitre propose un aperçu pratique, illustrant l'utilisation d'algorithmes d'apprentissage automatique pour résoudre des problèmes concrets. Cela inclut la prédiction de valeurs à l'aide de l'apprentissage supervisé, ainsi que le regroupement de données à travers l'apprentissage non supervisé. Bien que des données synthétiques soient utilisées à des fins d'illustration, dans des applications réelles, les données utilisées sont plus complexes.
4.1 Exemple d'Apprentissage Supervisé (Régression Linéaire)
Un exemple concret d'apprentissage supervisé est la prédiction des notes d'étudiants en fonction du nombre d'heures de révision. Nous allons utiliser une régression linéaire, un algorithme couramment utilisé pour ce type de tâche, en utilisant le langage de programmation Python avec la bibliothèque scikit-learn.
Un modèle de régression linéaire est entraîné sur l'ensemble d'entraînement pour apprendre la relation entre les notes d'étudiants et le nombre d'heures de révision. Les prédictions sont ensuite effectuées sur l'ensemble de test. Voici un exemple de code Python avec des explications pour chaque étape :
Importation des bibliothèques nécessaires, notamment scikit-learn pour les modèles d'apprentissage automatique. A noter qu’il est nécessaire d’installer la bibliothèque scikit-learn en utilisant la commande `python -mpip install scikit-learn` avant d'exécuter le code.
Création de données d'exemple avec un bruit pour simuler des notes d'examen en fonction du temps d'étude.
Division des données en ensembles d'entraînement et de test.
Création et entrainement d'un modèle de régression linéaire.
Faire des prédictions sur les données de test.
Évaluation des performances du modèle en utilisant l'erreur quadratique moyenne.
Visualisation des résultats avec un nuage de points réels et une ligne de régression linéaire.
4.2 Exemple d'Apprentissage Non Supervisé (K-Means)
Voici un exemple simple d'apprentissage non supervisé avec le clustering K-Means en utilisant Python et la bibliothèque scikit-learn. Le but est de regrouper des données en clusters sans étiquettes prédéfinies. Dans cet exemple, nous générons d'abord des données synthétiques avec la fonction `make_blobs` et les visualisons. Ensuite, nous appliquons l'algorithme K-Means avec KMeans de scikit-learn. Enfin, nous visualisons les résultats du clustering avec différents clusters colorés et les centres de cluster en rouge. Voici une explication détaillée de chaque étape :
Importation des bibliothèques nécessaires, dont NumPy pour le traitement numérique, Matplotlib pour la visualisation, et les modules KMeans et make_blobs de scikit-learn.
Génération d’un ensemble de données synthétiques avec make_blobs. X contient les coordonnées des points, et y contient les étiquettes des clusters (mais elles ne seront pas utilisées dans cet exemple).
Visualisation des données générées avec un nuage de points en deux dimensions.
Application de l'algorithme de K-Means : Nous créons une instance de l'algorithme K-Means avec n_clusters=4 pour spécifier le nombre de clusters que nous voulons. Ensuite, nous adaptons l'algorithme aux données.
Obtention des centres de cluster et des labels : Nous obtenons les coordonnées des centres de cluster et les labels attribués à chaque point dans les données.
Visualisation des résultats du clustering K-Means en attribuant différentes couleurs aux points en fonction de leurs labels. Les centres de cluster sont marqués en rouge.
4.3 Opinions et classification de textes
Dans les exemples précédents, nous avons exploré l'application de la classification à des données numériques. À présent, nous allons examiner son utilité dans le contexte du traitement de texte. La classification de texte trouve des applications diverses, telles que la recommandation de publicités ou d'articles en fonction du contenu lié aux recherches sur Internet ou aux discussions sur les réseaux sociaux, ainsi que l'évaluation de l'opinion des internautes sur des sujets spécifiques au sein des médias sociaux, etc.
Pour illustrer ce concept, voici un exemple concret qui inclut une explication détaillée de chaque étape, mettant en œuvre la classification des opinions avec scikit-learnà l'aide du classificateur Naive Bayes.
Installation des bibliothèques :
Préparation des données : Créez un ensemble de données avec des avis positifs et négatifs :
Création des caractéristiques (features) : Utilisez un sac de mots pour représenter les opinions :
Division des données en ensembles d'entraînement et de test :
Entraînement du modèle
Prédiction et évaluation
Afficher les résultats
Exemple d'utilisation du modèle entraîné pour prédire une nouvelle opinion
Ce code peut être adapté en fonction de la complexité de l’ensemble de données des exigences spécifiques du problème d'analyse des opinions.
5. Conclusion
L'intelligence artificielle est un domaine vaste et en constante évolution. Il est crucial d'avoir une compréhension des principes fondamentaux pour aborder efficacement des projets et comprendre les ressources disponibles. Cet article vise à fournir un point d'entrée pour comprendre et mettre en œuvre des projets liés à l'intelligence artificielle, notamment en ce qui concerne le Machine Learning. Il sera suivi par un autre article qui se concentrera sur le Deep Learning, notamment les réseaux de neurones. Pour une meilleure compréhension des algorithmes théoriques, nous avons compté sur Python pour présenter quelques exemples pratiques. Bien que de nombreux concepts aient été abordés de manière concise, l'objectif principal était d’établir une base en vue de poursuivre l'exploration dans ce domaine.
Références :
Intelligence artificielle vulgarisée Le Machine Learning et le Deep Learning par la pratique : Aurélien Vannieuwenhuyze
Introduction to Machine Learning with Python: A Guide for Data Scientists par Andreas C. Müller et Sarah Guido.